GalileoNews

Carburante sporco, chi paga in caso di danni al motore? Scopri cosa dice la legge
Inserire del carburante sporco nella vettura comporta dei danni gravissimi al motore, per questo si può chiedere il risarcimento. Chi paga? Chi possiede un veicolo …


World

Oroscopo, se vuoi conquistare un uomo della Vergine questo è tutto quello che devi sapere: non farti trovare impreparato
Se ti sei innamorata di un uomo del segno della Vergine sappi che conquistarlo non …

Puoi finalmente dire addio alle fastidiose mosche in casa: una volta provato non rinuncerai mai più a questo antico metodo
Arriva il caldo e con esso le mosche. Ecco come dire addio a questi insetti: …

Le tarme sono tornate? Basta spray chimici: prova questo rimedio naturale e te ne sbarazzi per sempre
Il problema delle tarme è ricorrente e quindi è essenziale capire come gestire la situazione …

Le cimici sono tornate ad infastidirci: con questo trucco non le troverai più nel tuo bucato
Tempo di cimici e quindi anche di fare attenzione al bucato per evitare di ritrovarsele …

Quando finisce un amore: 3+1 cose da fare per superare la conclusione della tua relazione
Hai chiuso la tua love story e ora sei tornato ad essere single come un …
Gossip News

Oroscopo, momento terribile per questi segni: come muoversi per evitare il peggio
L’oroscopo riserva non poche difficoltà ad alcuni segni in questo periodo: ecco i suggerimenti per …

Sandra Milo, spunta fuori la terribile verità: da anni l’accompagnava un grosso dolore
Sandra Milo ha vissuto un dolore che non l’ha fatta stare serena per diversi anni: …

Oroscopo, sono questi i segni più scontrosi e nervosi dello Zodiaco: con loro è impossibile spuntarla
I segni più scontrosi dello Zodiaco sono davvero difficili da trattare: a volte si comportano …

Vladimir Luxuria in bikini, il volto inedito della conduttrice: eccola a riflettori spenti
Lontano dalle riprese e dagli studi televisivi, Vladimir Luxuria si mostra lontana dallo stress delle …

“Appena nato”, Antonella Clerici pazza di gioia: l’annuncio fa sognare i fan
La famosa conduttrice di È sempre mezzogiorno e The Voice Antonella Clerici ha condiviso un …
Tech

Il telecomando della auto non funziona? Ecco cosa fare per sbloccare la situazione
Il telecomando dell’auto che non funziona più è un problema molto serio ma c’è un …

WhatsApp in rivoluzione: il nuovo suggerimento dell’app cambia tutto
Tante le novità “in cantiere” per il servizio di messaggistica di Meta, alcune già rilasciate …
Ricchi rimborsi da Tim, WindTre, Vodafone e Fastweb: ecco come averli subito
Ricchi rimborsi in arrivo da TIM, WindTre, Vodafone e Fastweb! Ecco tutto ciò che devi …
Sport

Il digiuno è un toccasana per tutto il corpo: 6 effetti miracolosi sull’organismo
Il digiuno è un vero toccasana per il nostro corpo. Ecco 6 effetti miracolosi sull’organismo …

Nuovissimo Bonus Sport con cifre alte: gara di velocità per la scadenza del 22 aprile
Ottime notizie per tutti gli appassionati di sport e non: è possibile fare richiesta per …

Chris Paul ritorna per i Phoenix Suns
Chris Paul è tornato. La stella dei Phoenix Suns in campo contro i Los Angeles …
Fashion
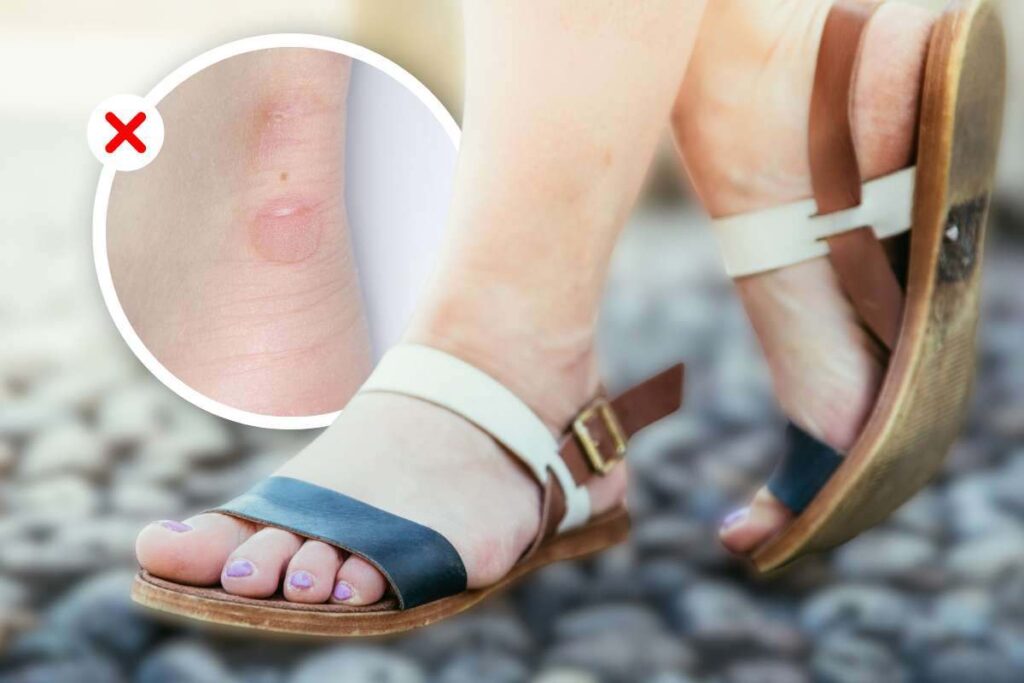
In primavera tornano le scarpe aperte: come evitare le vesciche? I trucchi infallibili
Arriva la stagione calda e con essa le scarpe aperte! Purtroppo però tornano anche le …

Addio capelli bianchi: come risolvere il problema con prodotti naturali: il risultato è sorprendente
Se hai i capelli bianchi ma non vuoi usare tinture chimiche e aggressive, ecco quali …
Business

Carburante sporco, chi paga in caso di danni al motore? Scopri cosa dice la legge
Inserire del carburante sporco nella vettura comporta dei danni gravissimi al motore, per questo si …

Legge 104 si trasforma in una trappola: arrivano i durissimi controlli analitici
Arriva la stretta dell’INPS sulle agevolazioni della Legge 104. Ecco per quale motivo i beneficiari …